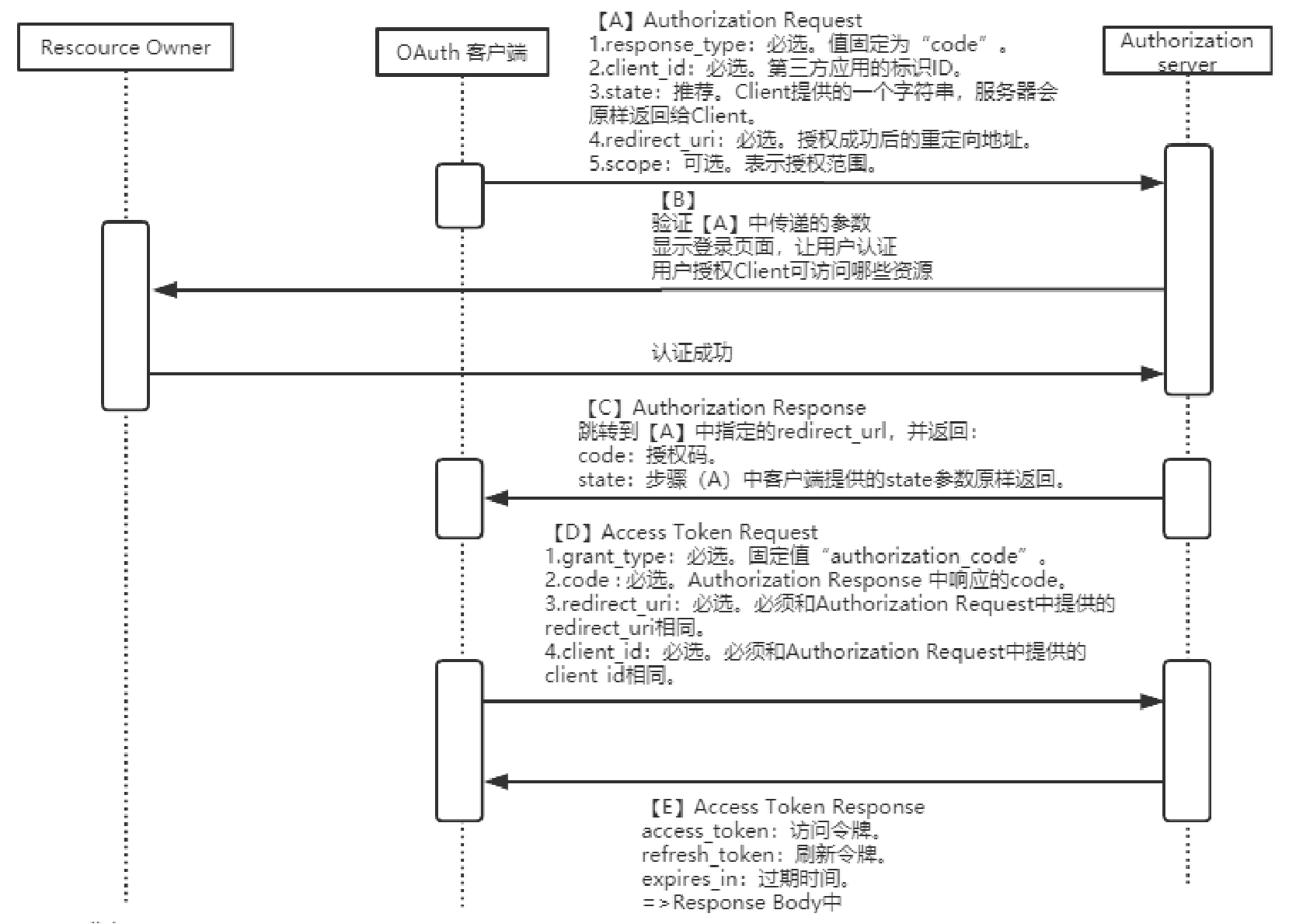
用户每次在首页推荐获取10个帖子,下拉刷新,每次刷新产生的帖子记录成日志,日志内容包含10个帖子的id,日志的信息会发送到 MQ ,用于消费。
需求:
给用户展示最近 24 小时曝光 top 100 的帖子,注意24小时是一个滑动窗口:每次读取都是最近24小时的曝光统计结果(不用精确到秒,最大延迟不应该超过10分钟)
线上用户读取结果时,接口时延 P99 应该控制在 200ms 以下(忽略高并发问题,假设 qps=1)
数量级:4000 万日志,4 亿条曝光,100万帖子
定义服务
- 帖子推荐服务
存储
- 结合数据量大、但是对 QPS 要求不高,接口响应时间要求高。
方案
方案1
- 消费MQ,按10分钟维度去建立缓存,例如:id_202211251620 ,value就上一个窗口减去24小时前的窗口值,窗口期累积,并比较判断是否能计入top100 的zset,用户取zset就行
方案2
- 经典 Flink 计算 topn 问题
方案3
- 两个流 一个曝光流 一个过期流 一个加1 一个减1